Imagine this: Creating new visual concepts by recombining familiar ones
Around two and a half thousand years ago a Mesopotamian trader gathered some clay, wood and reeds and changed humanity forever. Over time, their abacus would allow traders to keep track of goods and reconcile their finances, allowing economics to flourish.
But that moment of inspiration also shines a light on another astonishing human ability: our ability to recombine existing concepts and imagine something entirely new. The unknown inventor would have had to think of the problem they wanted to solve, the contraption they could build and the raw materials they could gather to create it. Clay could be moulded into a tablet, a stick could be used to scratch the columns and reeds can act as counters. Each component was familiar and distinct, but put together in this new way, they formed something revolutionary.
This idea of “compositionality” is at the core of human abilities such as creativity, imagination and language-based communication. Equipped with just a small number of familiar conceptual building blocks, we are able to create a vast number of new ones on the fly. We do this naturally by placing concepts in hierarchies that run from specific to more general and then recombining different parts of the hierarchy in novel ways.
But what comes so naturally to us, remains a challenge in AI research.
In our new paper, we propose a novel theoretical approach to address this problem. We also demonstrate a new neural network component called the Symbol-Concept Association Network (SCAN), that can, for the first time, learn a grounded visual concept hierarchy in a way that mimics human vision and word acquisition, enabling it to imagine novel concepts guided by language instructions.
Our approach can be summarised as follows:
- The SCAN model experiences the visual world in the same way as a young baby might during the first few months of life. This is the period when the baby’s eyes are still unable to focus on anything more than an arm’s length away, and the baby essentially spends all her time observing various objects coming into view, moving and rotating in front of her. To emulate this process, we placed SCAN in a simulated 3D world of DeepMind Lab, where, like a baby in a cot, it could not move, but it could rotate its head and observe one of three possible objects presented to it against various coloured backgrounds - a hat, a suitcase or an ice lolly. Like the baby’s visual system, our model learns the basic structure of the visual world and how to represent objects in terms of interpretable visual “primitives”. For example, when looking at an apple, the model will learn to represent it in terms of its colour, shape, size, position or lighting.

SCAN learns to represent a visual scene in terms of basic interpretable visual primitives, such as object identity, colour and rotation, wall colour, floor colour and others.
- Once our model is able to parse the visual world in terms of interpretable visual primitives, we enter the naming stage of the learning process. This is equivalent to word learning in infants, when adults start to provide symbolic word labels for the various visual objects the infant is seeing. For example, during this stage a parent might point their baby towards an apple with the words: “Look, an apple!”. Similarly, SCAN’s experiences within DeepMind Lab are augmented with basic language input, so an image of a red suitcase presented against a yellow wall would be accompanied by a symbolic input like “red suitcase, yellow wall”. SCAN is able to learn the meaning of a new concept by building an abstraction over the visual primitives it learnt in the previous stage. For example, the concept of an apple might be specified in terms of its colour, shape and size, while other visual primitives, such as position and lighting, are correctly identified as being irrelevant to the concept of an apple.
- This naming process can be used to learn visual concepts from anywhere in the hierarchy. The same process can also be used to teach the model the meaning of concept recombination operators, such as “and”, “ignore”, and “in common”, by showing it a small number of examples of how they are correctly used. For example, the meaning of “and” can be taught by showing SCAN an image of a “golden delicious” apple paired with an instruction: “golden delicious IS yellow AND apple”.
- Once SCAN has learnt a vocabulary of concepts and a way to manipulate them through symbolic instructions, it can be verbally instructed to combine familiar concepts into new ones without needing any more images as examples. Through these instructions, SCAN can imagine a large number of novel visual concepts on the fly, such as blue apples (“blue AND apple”) or different kinds of apples (“granny smith IS golden delicious IGNORE yellow, AND green”).
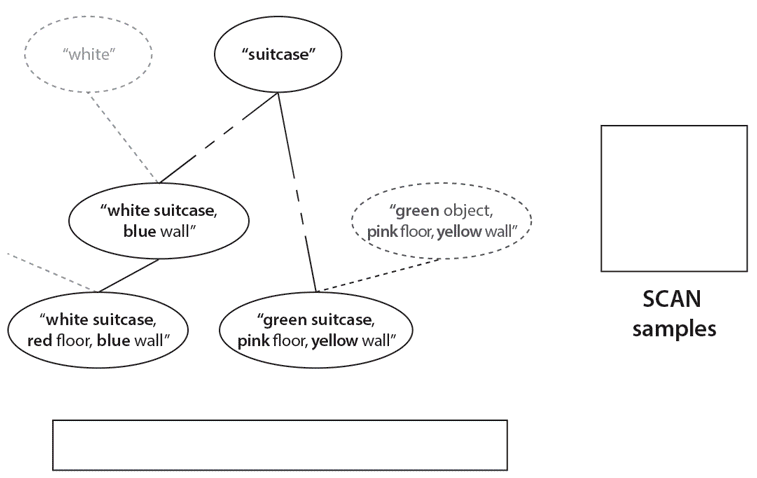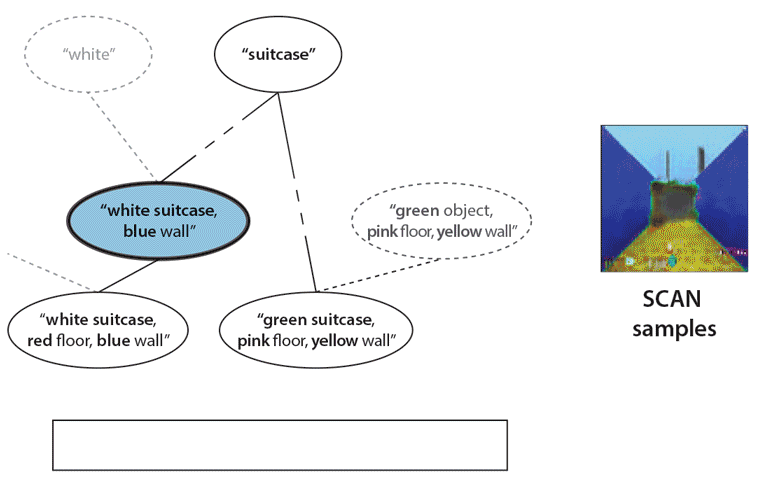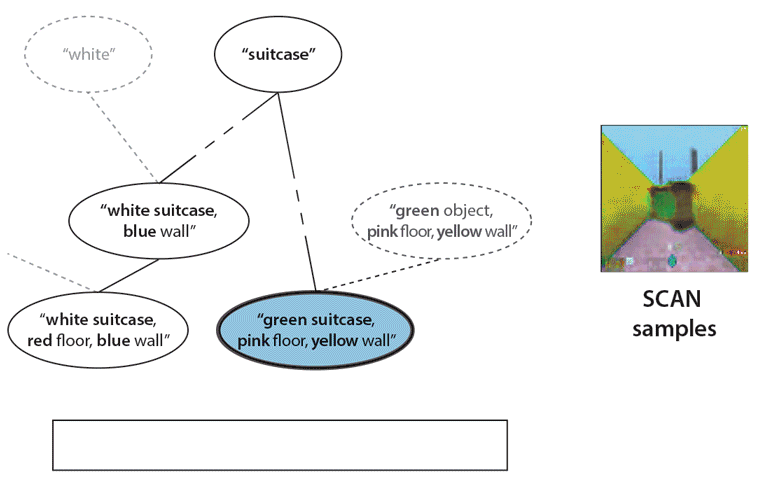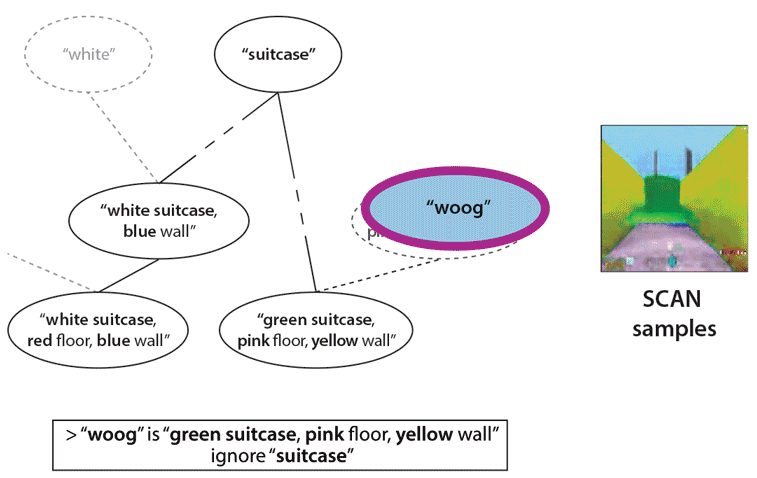
First SCAN traverses the concept hierarchy through language instructions, from the more specific concept corresponding to a “white suitcase in a blue room with a red floor”, to a more general concept of “suitcase” and back to a more specific concept “green suitcase in a yellow room with a pink floor”. At each step SCAN is asked to imagine the corresponding concept (shown on the right). Finally, SCAN is instructed the meaning of a new concept, “woog”. Having never seen an example of a “woog”, SCAN can successfully imagine what they might look like (a green object in a yellow room with a pink floor).
Our approach differs from previous work in this area because it is fully grounded in the sensory data and learns from very few image-word pairs. While other deep learning approaches require thousands of image examples to learn a concept, SCAN learns both the visual primitives and conceptual abstractions primarily from unsupervised observations and as few as five pairs of an image and label per concept. Once trained, SCAN can then generate a diverse list of concepts that correspond to a particular image, and imagine diverse visual examples that correspond to a particular concept, even if it has never experienced the concept before.

On the left SCAN imagines what a “white suitcase” might look like. On the right SCAN produces concepts from across the full hierarchy that correspond to the image of a cyan hat in a pink room with an orange floor.
This ability to learn new concepts by recombining existing ones through symbolic instructions has given humans astonishing abilities, allowing us to reason about abstract concepts like the universe, humanism or - as was the case in Mesopotamia - economics. While our algorithms have a long way to go before they can make such conceptual leaps, this work demonstrates a first step towards having algorithms that can learn in a largely unsupervised way, and think about conceptual abstractions like those used by humans.
Notes
Read paper: SCAN: Learning Abstract Hierarchical Compositional Visual Concepts