Dopamine and temporal difference learning: A fruitful relationship between neuroscience and AI

Learning and motivation are driven by internal and external rewards. Many of our day-to-day behaviours are guided by predicting, or anticipating, whether a given action will result in a positive (that is, rewarding) outcome. The study of how organisms learn from experience to correctly anticipate rewards has been a productive research field for well over a century, since Ivan Pavlov's seminal psychological work. In his most famous experiment, dogs were trained to expect food some time after a buzzer sounded. These dogs began salivating as soon as they heard the sound, before the food had arrived, indicating they'd learned to predict the reward. In the original experiment, Pavlov estimated the dogs’ anticipation by measuring the volume of saliva they produced. But in recent decades, scientists have begun to decipher the inner workings of how the brain learns these expectations. Meanwhile, in close contact with this study of reward learning in animals, computer scientists have developed algorithms for reinforcement learning in artificial systems. These algorithms enable AI systems to learn complex strategies without external instruction, guided instead by reward predictions.
The contribution of our new work, published in Nature (PDF), is finding that a recent development in computer science – which yields significant improvements in performance on reinforcement learning problems – may provide a deep, parsimonious explanation for several previously unexplained features of reward learning in the brain, and opens up new avenues of research into the brain’s dopamine system, with potential implications for learning and motivation disorders.
A chain of prediction: temporal difference learning
Reinforcement learning is one of the oldest and most powerful ideas linking neuroscience and AI. In the late 1980s, computer science researchers were trying to develop algorithms that could learn how to perform complex behaviours on their own, using only rewards and punishments as a teaching signal. These rewards would serve to reinforce whatever behaviours led to their acquisition. To solve a given problem, it’s necessary to understand how current actions result in future rewards. For example, a student might learn by reinforcement that studying for an exam leads to better scores on tests. In order to predict the total future reward that will result from an action, it's often necessary to reason many steps into the future.
An important breakthrough in solving the problem of reward prediction was the temporal difference learning (TD) algorithm. TD uses a mathematical trick to replace complex reasoning about the future with a very simple learning procedure that can produce the same results. This is the trick: instead of trying to calculate total future reward, TD simply tries to predict the combination of immediate reward and its own reward prediction at the next moment in time. Then, when the next moment comes, bearing new information, the new prediction is compared against what it was expected to be. If they’re different, the algorithm calculates how different they are, and uses this “temporal difference” to adjust the old prediction toward the new prediction. By always striving to bring these numbers closer together at every moment in time – matching expectations to reality – the entire chain of prediction gradually becomes more accurate.
Around the same time, in the late 80s and early 90s, neuroscientists were struggling to understand the behaviour of dopamine neurons. Dopamine neurons are clustered in the midbrain, but send projections to many brain areas, potentially broadcasting some globally relevant message. It was clear that the firing of these neurons had some relationship to reward, but their responses also depended on sensory input, and changed as the animals became more experienced in a given task.
Fortuitously, some researchers were versed in the recent developments of both neuroscience and AI. These scientists noticed, in the mid-1990s, that responses in some dopamine neurons represented reward prediction errors–their firing signalled when the animal got more reward, or less reward, than it was trained to expect. These researchers therefore proposed that the brain uses a TD learning algorithm: a reward prediction error is calculated, broadcast to the brain via the dopamine signal, and used to drive learning. Since then, the reward prediction error theory of dopamine has been tested and validated in thousands of experiments, and has become one of the most successful quantitative theories in neuroscience.
Distributional reinforcement learning

Figure 1: When the future is uncertain, future reward can be represented as a probability distribution. Some possible futures are good (teal), others are bad (red). Distributional reinforcement learning can learn about this distribution over predicted rewards through a variant of the TD algorithm.
Computer scientists have continued to improve the algorithms for learning from rewards and punishments. Since 2013, there’s been a focus on deep reinforcement learning: using deep neural networks to learn powerful representations in reinforcement learning. This has enabled reinforcement learning algorithms to solve tremendously more sophisticated and useful problems.
One of the algorithmic developments that has made reinforcement learning work better with neural networks is distributional reinforcement learning. In many situations (especially in the real world), the amount of future reward that will result from a particular action is not a perfectly known quantity, but instead involves some randomness. An example is shown in Figure 1. This is a stylised representation of a situation where a computer-controlled avatar, trained to traverse an obstacle course, jumps across a gap. The agent is uncertain about whether it will fall, or reach the other side. Therefore, the distribution of predicted rewards has two bumps: one representing the possibility of falling, and one representing the possibility of successfully reaching the other side.
In such situations, a standard TD algorithm learns to predict the future reward that will be received on average–in this case, failing to capture the two-peaked distribution of potential returns. A distributional reinforcement learning algorithm, on the other hand, learns to predict the full spectrum of future rewards. Figure 1 depicts the reward prediction learned by a distributional agent.
A spectrum of pessimistic and optimistic predictions
One of the simplest distributional reinforcement learning algorithms is very closely related to standard TD, and is called distributional TD. Whereas standard TD learns a single prediction – the average expected reward – a distributional TD network learns a set of distinct predictions. Each of these is learned through the same method as standard TD – by computing a reward prediction error that describes the difference between consecutive predictions. But the crucial ingredient is that each predictor applies a different transformation to its reward prediction errors. Some predictors "amplify" or "overweight" their reward prediction errors (RPE) selectively when the reward prediction error is positive (Figure 2a). This causes the predictor to learn a more optimistic reward prediction, corresponding to a higher part of the reward distribution. Other predictors amplify their negative reward prediction errors (Figure 2a), and so learn more pessimistic predictions. All together, a set of predictors with a diverse set of pessimistic and optimistic weightings map out the full reward distribution (Figure 2b, 2c).
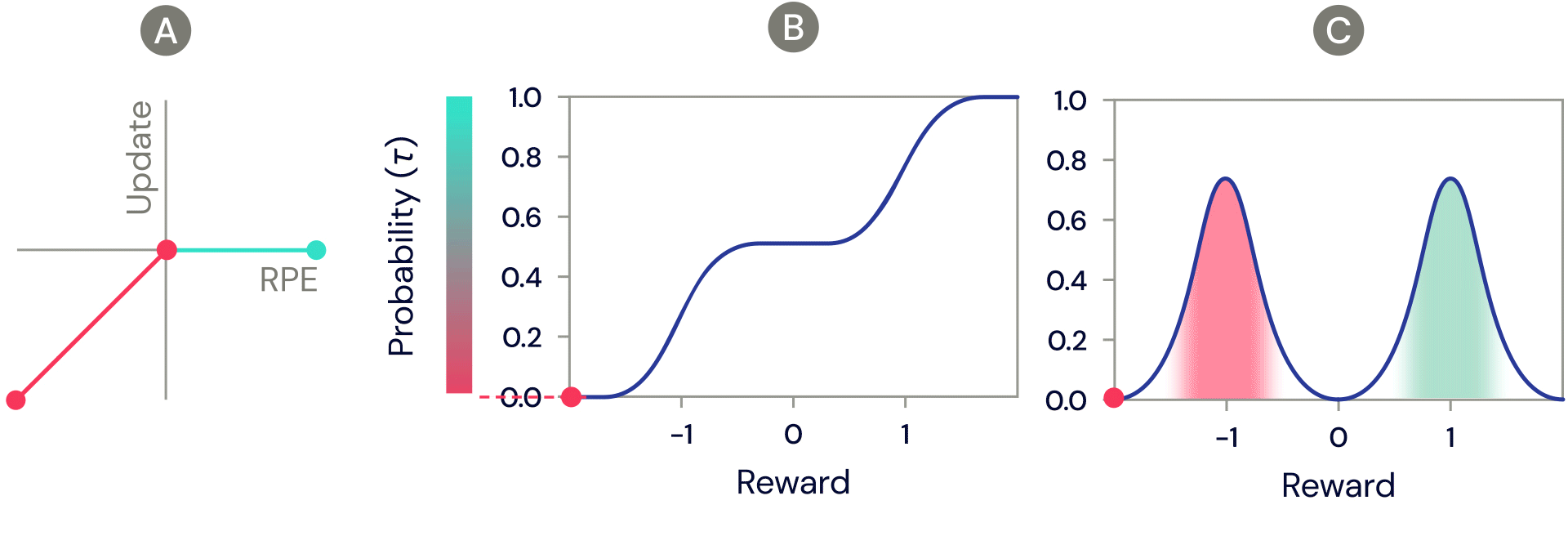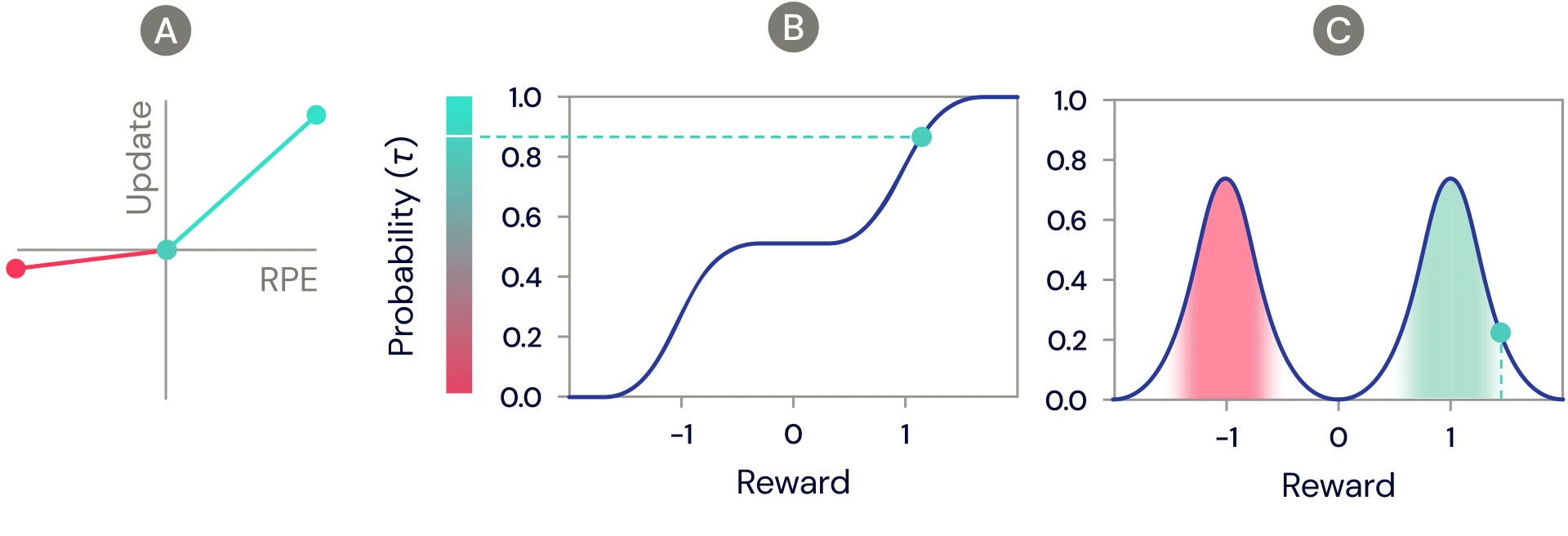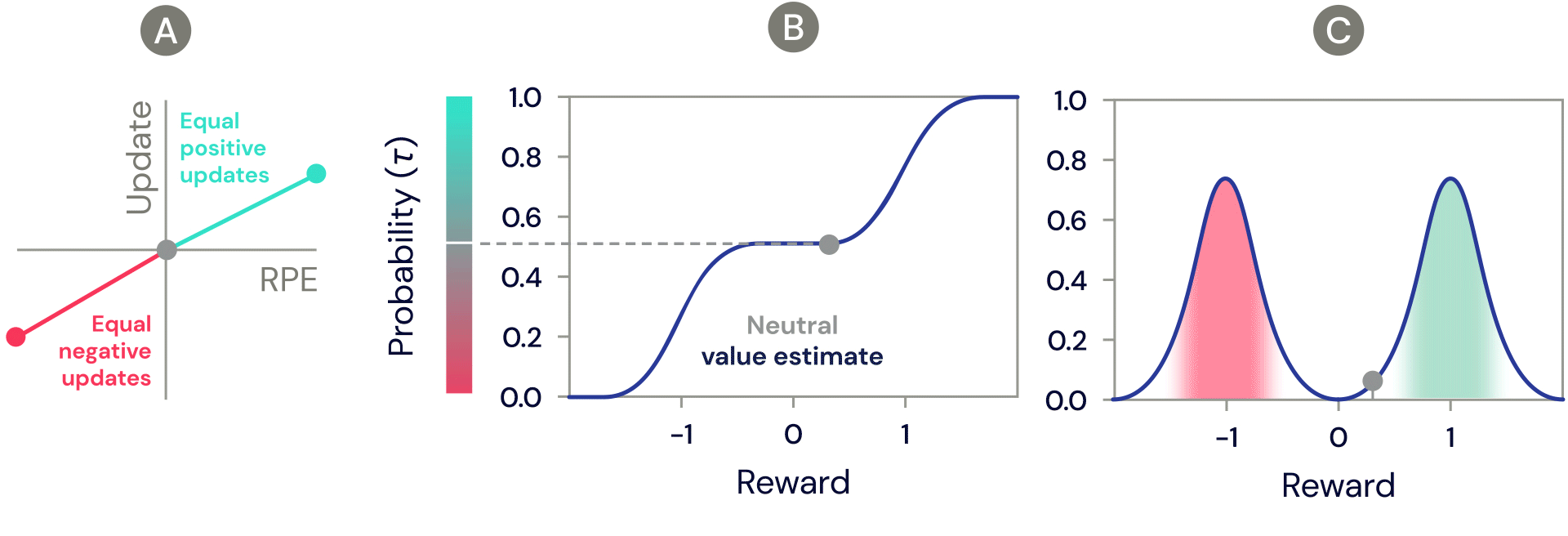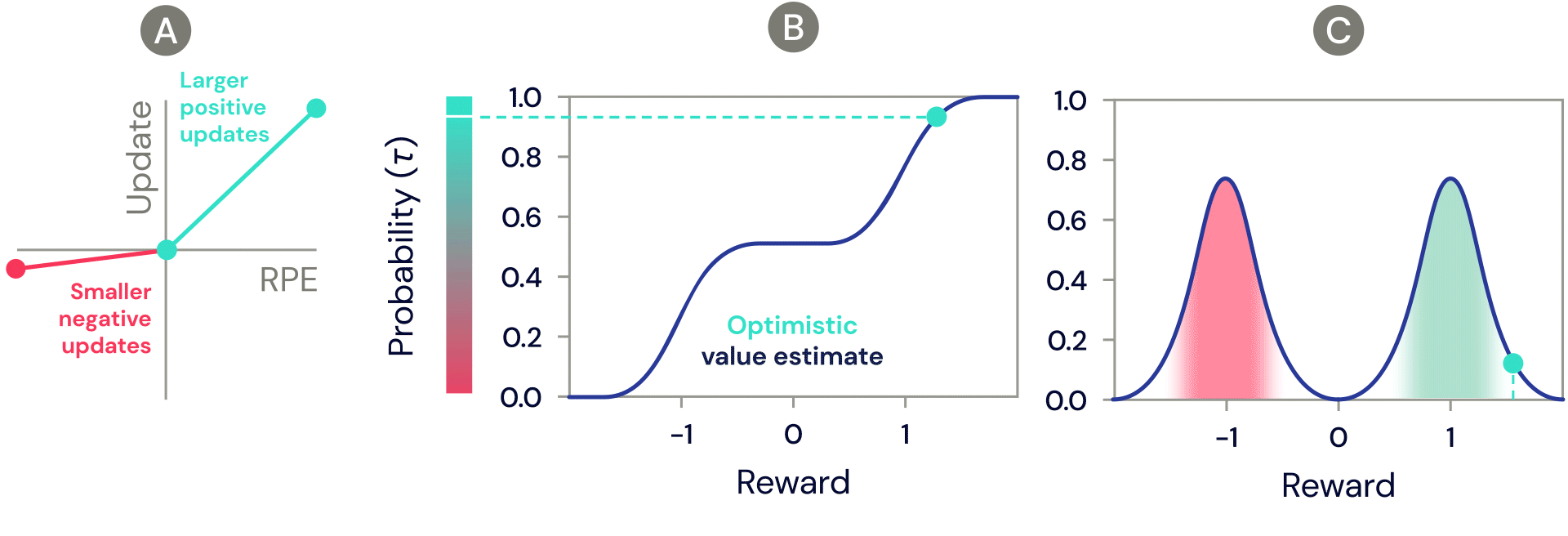
Figure 2: Distributional TD learns value estimates for many different parts of the distribution of rewards. Which part a particular estimate covers is determined by the type of asymmetric update applied to that estimate. (A) A ‘pessimistic’ cell would amplify negative updates and ignore positive updates, an ‘optimistic’ cell would amplify positive updates and ignore negative updates. (B) This results in a diversity of pessimistic or optimistic value estimates, shown here as points along the cumulative distribution of rewards, that capture (C) the full distribution of rewards.

Figure 3: Median human-normalised scores on the Atari-57 benchmark contrasting recent research in deep (teal) and distributional (blue) reinforcement learning.
Aside from its simplicity, another benefit of distributional reinforcement learning is that it’s very powerful when combined with deep neural networks. In the last 5 years, there’s been a great deal of progress in algorithms based around the original deep reinforcement learning DQN agent, and these are frequently evaluated on the Atari-57 benchmark set of Atari 2600 games. Figure 3 compares many standard and distributional RL algorithms, trained and evaluated under the same conditions, on this benchmark. Distributional reinforcement learning agents are shown in blue, and illustrate the significant pattern of improvements. Three of these algorithms (QR-DQN, IQN, and FQF) are variants of the distributional TD algorithm we’ve been discussing.
Why are distributional reinforcement learning algorithms so effective? Although this is still an active topic of research, a key ingredient is that learning about the distribution of rewards gives the neural network a more powerful signal for shaping its representation in a way that’s robust to changes in the environment or changes in the policy.
A distributional code in dopamine
Because distributional TD is so powerful in artificial neural networks, a natural question arises: Is distributional TD used in the brain? This was the driving question behind our paper recently published in Nature.
In this work, we collaborated with an experimental lab at Harvard to analyse their recordings of dopamine cells in mice. The recordings were made while the mice performed a well-learned task in which they received rewards of unpredictable magnitude (indicated by the dice illustration in Figure 4). We evaluated whether the activity of dopamine neurons was more consistent with standard TD or distributional TD.
As described above, distributional TD relies on a set of distinct reward predictions. Our first question was whether we could see such genuinely diverse reward predictions in the neural data.
From previous work, we know that dopamine cells change their firing rate to indicate a prediction error – that is, if an animal receives more or less reward than it expected. We know that there should be zero prediction error when a reward is received that is the exact size as what a cell had predicted, and therefore no change in firing rate. For each dopamine cell, we determined the reward size for which it didn’t change its baseline firing rate. We call this the cell's "reversal point". We wanted to know whether these reversal points were different between cells. In Figure 4c, we show that there were marked differences between cells, with some cells predicting very large amounts of reward, and other cells predicting very little reward. These differences were above and beyond the amount of difference we would expect to see from random variability inherent in the recordings.

Figure 4: In this task, mice are given water rewards of a randomly determined, variable amount, ranging in magnitude from 0.1 uL to 20 uL (indicated by the dice linked to the reward amounts). (A) The responses of simulated dopamine cells to the seven different reward magnitudes under a classic TD model, and (B) under a distributional TD model. Each row of dots corresponds to a dopamine cell, and each color corresponds to a different reward size. Colored curves indicate spline interpolations of the data. A cell’s reversal point (where its reward prediction error firing rate crosses zero) is the reward amount which that particular cell is ‘tuned’ to expect – e.g., the reward amount for which a cell will not fire more or less than its baseline rate, because its expectation was met. (C) The responses of real dopamine cells to the seven different reward magnitudes closely match the distributional TD model’s prediction. Insets show three example cells with different relative scaling of positive and negative reward prediction errors.
In distributional TD, these differences in reward prediction arise from selective amplification of positive or negative reward prediction errors. Amplifying positive reward prediction errors causes more optimistic reward predictions to be learned; amplifying negative reward prediction errors causes pessimistic predictions. So we next measured the degree to which different dopamine cells exhibited different relative amplifications of positive versus negative expectations. Between cells, we found reliable diversity which, again, could not be explained by noise. And, crucially, we found that the same cells which amplified their positive reward prediction errors also had higher reversal points (Figure 4c, bottom-right panels) – that is, they were apparently tuned to expect higher reward volumes.

Figure 5: As a population, dopamine cells encode the shape of the learned reward distribution: we can decode the distribution of rewards from their firing rates. The gray shaded area is the true distribution of rewards encountered in the task. Each light blue trace shows an example run of the decoding procedure. Dark blue is the average over runs.
Finally, distributional TD theory predicts that these diverse reversal points and diverse asymmetries, across cells, should collectively encode the learned reward distribution. So our final question was if we could decode the reward distribution from the firing rates of dopamine cells. As shown in Figure 5, we found that it was indeed possible, using only the firing rates of dopamine cells, to reconstruct a reward distribution (blue trace) which was a very close match to the actual distribution of rewards (grey area) in the task that the mice were engaged in. This reconstruction relied on interpreting the firing rates of dopamine cells as the reward prediction errors of a distributional TD model, and performing inference to determine what distribution that model had learned about.
Conclusions
In summary, we found that dopamine neurons in the brain were each tuned to different levels of pessimism or optimism. If they were a choir, they wouldn’t all be singing the same note, but harmonizing – each with a consistent vocal register, like bass and soprano singers. In artificial reinforcement learning systems, this diverse tuning creates a richer training signal that greatly speeds learning in neural networks, and we speculate that the brain might use it for the same reason.
The existence of distributional reinforcement learning in the brain has interesting implications both for AI and neuroscience. Firstly, this discovery validates distributional reinforcement learning – it gives us increased confidence that AI research is on the right track, since this algorithm is already being used in the most intelligent entity we're aware of: the brain.
Secondly, it raises new questions for neuroscience, and new insights for understanding mental health and motivation. What happens if an individual's brain “listens” selectively to optimistic versus pessimistic dopamine neurons? Does this give rise to impulsivity, or depression? A strength of the brain is its powerful representations – how are these sculpted by distributional learning? Once an animal learns about the distribution of rewards, how is that representation used downstream? How does the variability of optimism across dopamine cells relate to other known forms of diversity in the brain?
Finally, we hope that asking and answering these questions will stimulate progress in neuroscience that will feed back to benefit AI research, completing the virtuous circle.