Objects that Sound
Visual and audio events tend to occur together: a musician plucking guitar strings and the resulting melody; a wine glass shattering and the accompanying crash; the roar of a motorcycle as it accelerates. These visual and audio stimuli are concurrent because they share a common cause. Understanding the relationship between visual events and their associated sounds is a fundamental way that we make sense of the world around us.
In Look, Listen, and Learn and Objects that Sound (to appear at ECCV 2018), we explore this observation by asking: what can be learnt by looking at and listening to a large number of unlabelled videos? By constructing an audio-visual correspondence learning task that enables visual and audio networks to be jointly trained from scratch, we demonstrate that:
- the networks are able to learn useful semantic concepts;
- the two modalities can be used to search one another (e.g. to answer the question, “Which sound fits well with this image?”); and
- the object making the sound can be localised.
Limitations of previous cross-modal learning approaches
Learning from multiple modalities is not new; historically, researchers have largely focused on image-text or audio-vision pairings. However, a common approach has been to train a “student” network in one modality using the automatic supervision provided by a “teacher” network in the other modality (“teacher-student supervision”), where the “teacher” has been trained using a large number of human annotations.
For instance, a vision network trained on ImageNet can be used to annotate frames of a YouTube video as “acoustic guitar”, which provides training data to the “student” audio network for learning what an “acoustic guitar” sounds like. In contrast, we train both visual and audio networks from scratch, where the concept of the “acoustic guitar” naturally emerges in both modalities. Somewhat surprisingly, this approach achieves superior audio classification compared to teacher-student supervision. As described below, this also equips us to localise the object making the sound, which was not possible with previous approaches.
Learning from cross-modal self-supervision
Our core idea is to use a valuable source of information contained in the video itself: the correspondence between visual and audio streams available by virtue of them appearing together at the same time in the same video. By seeing and hearing many examples of a person playing a violin and examples of a dog barking, and rarely or never seeing a violin being played while hearing a dog bark and vice versa, it should be possible to conclude what a violin and a dog look and sound like. This approach is, in part, motivated by the way an infant might learn about the world as their visual and audio capabilities develop.
We apply learning by audio-visual correspondence (AVC), a simple binary classification task: given an example video frame and a short audio clip, decide whether they correspond to each other or not.

The only way for a system to solve this task is by learning to detect various semantic concepts in both the visual and the audio domain. To tackle the AVC task, we propose the following network architecture

Audio-Visual Embedding Network (AVE-Net)
The image and the audio subnetworks extract visual and audio embeddings and the correspondence score is computed as a function of the distance between the two embeddings. If the embeddings are similar, the (image, audio) are deemed to correspond.
We show that the networks learn useful semantic representations, as, for example, our audio network sets the new state-of-the-art on two sound classification benchmarks. Since the correspondence score is computed purely based on the distance, the two embeddings are forced to be aligned (i.e. the vectors live in the same space, and so can be compared meaningfully), thus facilitating cross-modal retrieval:
Localising objects that sound
The AVE-Net recognises semantic concepts in the audio and visual domains, but it cannot answer the question, “Where is the object that is making the sound?” We again make use of the AVC task and show that it is possible to learn to localise sounding objects, while still not using any labels whatsoever.
To localise a sound in the image, we compute the correspondence scores between the audio embedding and a grid of region-level image descriptors. The network is trained with multiple instance learning – the image-level correspondence score is computed as the maximum of the correspondence score map:
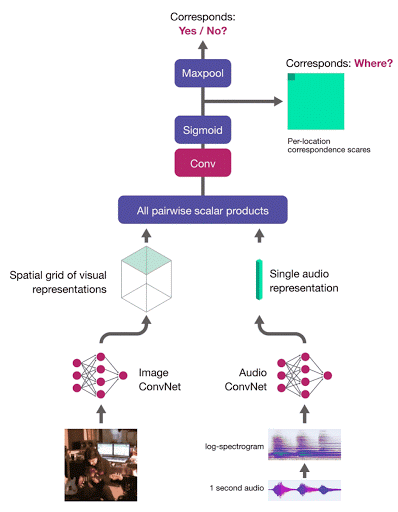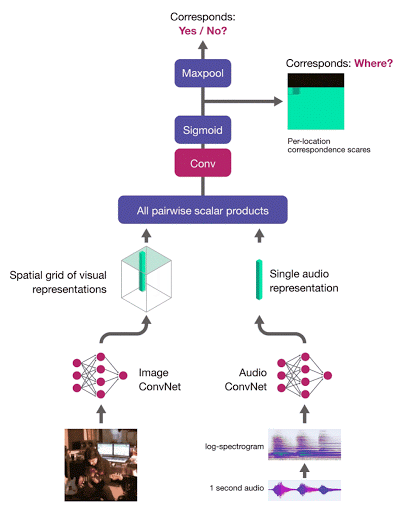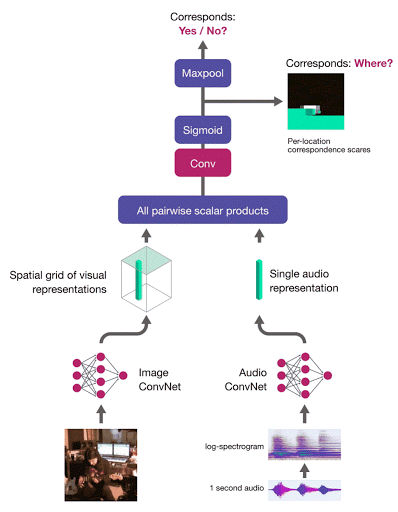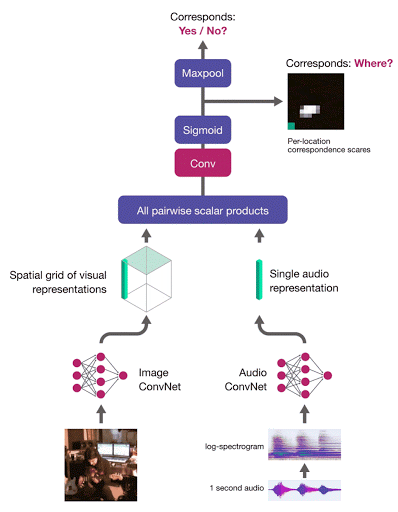
Audio-Visual Object Localisation Network (AVOL-Net)
For corresponding (image, audio) pairs, the method encourages at least one region to respond highly and therefore localise the object. In the below video (left - input frame, right - localisation output, middle - overlay), frames are processed completely independently – motion information is not used, and there is no temporal smoothing:
For mismatched pairs the maximal score should be low, thus making the entire score map dark, indicating, as desired, there is no object which makes the input sound:
The unsupervised audio-visual correspondence task enables, with appropriate network design, two entirely new functionalities to be learnt: cross-modal retrieval, and semantic-based localisation of objects that sound. Furthermore, it facilitates learning of powerful features, setting the new state-of-the-art on two sound classification benchmarks.
These techniques may prove useful in reinforcement learning, enabling agents to make use of large amounts of unlabelled sensory information. Our work may also have implications for other multimodal problems beyond audio-visual tasks in the future.
Notes
Read the full papers:
This work was done by Relja Arandjelović and Andrew Zisserman. Graphics by Adam Cain and Damien Boudot.